优化,还是过优化?
起因
在配置tmux的时候,我希望能看到温度、充电状态和点亮,这三个属性分别存放在三个文件中:
/sys/class/thermal/thermal_zone0/temp, /sys/class/power_supply/ACAD/online,
/sys/class/power_supply/BAT1/capacity中,并配置为这样的显示效果:
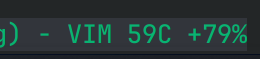
为了得到这样的效果,需要在.tmux.conf中配置一长串命令:
#(cut -c -2 /sys/class/thermal/thermal_zone0/temp)C #([ $(cat /sys/class/power_supply/ACAD/online) = 1 ] && echo +)#(cat /sys/class/power_supply/BAT1/capacity)%
开始优化
这实在是太长了!为了简化一些工作,我把显示温度单独抽了出来,用C语言写了一遍
1 |
|
然后使用gcc -O3 -s -o showtemp showtemp.c将其编译为了elf来替换上面打印温度的部分
继续优化
一段时间后,我回看这段命令,感觉仍然有点长,然后想到动不动就两三万的pid, 每3秒就要刷新一次,每次要起4个进程,还是太低效了。于是我直接把所有打印集成到一个程序中
1 |
|
这次我加入了这种边界判断,然后做了完善的测试,把所有打印功能集成到一个程序中, 然而...
陷入疯狂
当我在使用gdb调试程序的时候,我看到了熟悉的动态绑定:这个每天都要被运行几千次的程序,
还需要到ld里加载open等函数?疑似有点过于低效了!
我用gcc -S -o showtemp.s -O3 showtemp.c将程序转换为汇编,然后手动把call
open的地方转写为syscall,再编译:gcc -nostdlib -O3 -s -static -o showtemp showtemp.s
继续调试,发现程序不是线性运行的,因为编译器输出汇编时,分支跳转并不是按最高可能的情况输出的。 为此,我又加入了以下代码应用于分支判断加速
1 |
并且给整数变量前加上了register声明,最后再生成为汇编,并手动syscall,
得到了如下的汇编
1 | .file "showtemp.c" |
调试的时候也是成功使得程序运行时没有发生任何jmp
回顾
当我写完程序后,回过头来看花了过多的时间,因为汇编实在是晦涩难懂, 本来我还想着把逻辑梳理一遍,最后只把call转换成syscall就草草了事。而且, 花这么多时间来“优化”真的值得吗?本来程序运行就花不了多少毫秒,又是把程序转成汇编, 又是加各种优化的,并不能快多少。但是不优化的话,又让我感觉自己没有尽力, 这就是完美主义者的困扰吧。
最近又看到了关于cpu分支判断的文章,原先我以为分支判断错误惩罚是遇到了需要跳转的情况, 可事实上cpu会智能判断是否需要跳转,由此加速程序运行。考虑到优化到这种程序以后, 程序的瓶颈已经到syscall上了,这样的优化看起来就更没必要了。
就像网上说的,优化并不是以自己的范畴优化所有代码,而是重点优化影响系统运行的, 耗时的操作,将你的时间,用在更加重要的事上吧。
- 标题: 优化,还是过优化?
- 作者: RocketDev
- 创建于 : 2024-10-20 19:14:00
- 更新于 : 2024-10-20 19:14:00
- 链接: https://rocketma.dev/2024/10/20/over-optimize/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。